文件
1. GreenScreen危害終點
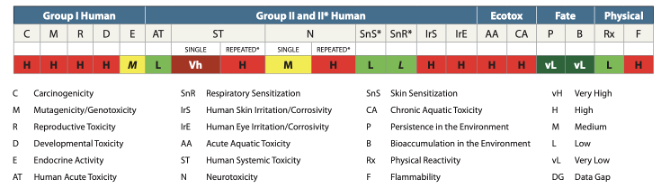
GreenScreen危害終點分為五大組,共有18個項目,分別為:
- 慢毒性危害 (5項):致癌性(C)、致突變性(M)、生殖毒性(R)、發育毒性(D)、內分泌活性(E)
- 急毒性危害 (7項):可分為單一暴露(single)或持續暴露(repeated*)。系統毒性與神經毒性這兩者危害終點有區分為單一暴露與持續暴露兩類,其他則僅屬於單一類別。#單一暴露:(哺乳類)急性毒性(AT)、全身毒性 - 單次劑量(ST)、神經毒性 - 單次劑量(N)、皮膚刺激(IrS)、眼睛刺激(IrE)。#持續暴露:皮膚致敏 - 重複劑量(SnS*)、呼吸致敏 - 重複劑量(SnR*)、全身毒性 - 重複劑量(ST*)、神經毒性 - 重複劑量(N*)。
- 環境危害 (2項):急性水生毒性(AA)、慢性水生毒性(CA)。
- 環境流佈 (2項):持續性(P)、生物累積性(B)。
- 物理危害 (2項):反應性(Rx)、可燃性(F)。
2. 以化學品清單制定GreenScreen危害等級分數
GreenScreen危害等級分數評估方式是參考GreenScreen Guideline v1.4中的附錄一「化學品危害準則」所列出來自不同國家、政府機構或非政府組織的化學品清單,將各個清單所區分之危害分類對應到GreenScreen對於化學品危害程度區分出的五個等級分數,分別為:非常高危害(vH)、高危害(H)、中等危害(M)、低危害(L)、非常低危害(vL)。GreenScreen另針對這些化學品清單所使用的研究及資料來源,訂定化學品清單的可信度標準。針對化學品列出關注相同危害終點的所有化學品清單所提供之危害資料,依化學品清單之可信度以及危害等級保守估計之原則來比較,最後給予化學品在十八項危害終點各一個危害等級分數。
以下以職業與環境診所協會 - 氣喘原清單化學品清單為例說明:
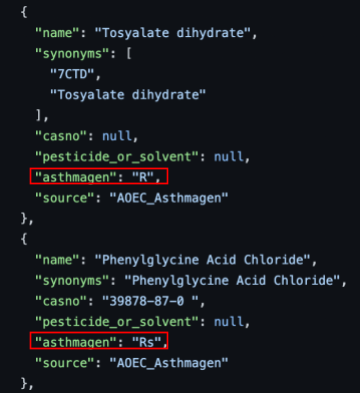
- 將化學品清單以轉換成JSON格式處理。
- 每個化學品清單都有各自針對所關注的危害類型將化學品分類的標準及相對應的欄位。
- 以職業與環境診所協會 - 氣喘原清單為例,將asthmagen類型分為:’G’, ‘Rr, ‘Rs’, ‘Rrs’ 四類。因此對於清單內所有的化學品,需要取出該欄位的資料來對應GreenScreen Guideline中的化學品危害準則來給予危害等級分數。
「化學品危害準則」圖示。從Information Source找到所需之化學品清單,並找到清單中不同分類對應到的危害等級分數,如:高危害(H)、中等危害(M)、低危害(L)…。
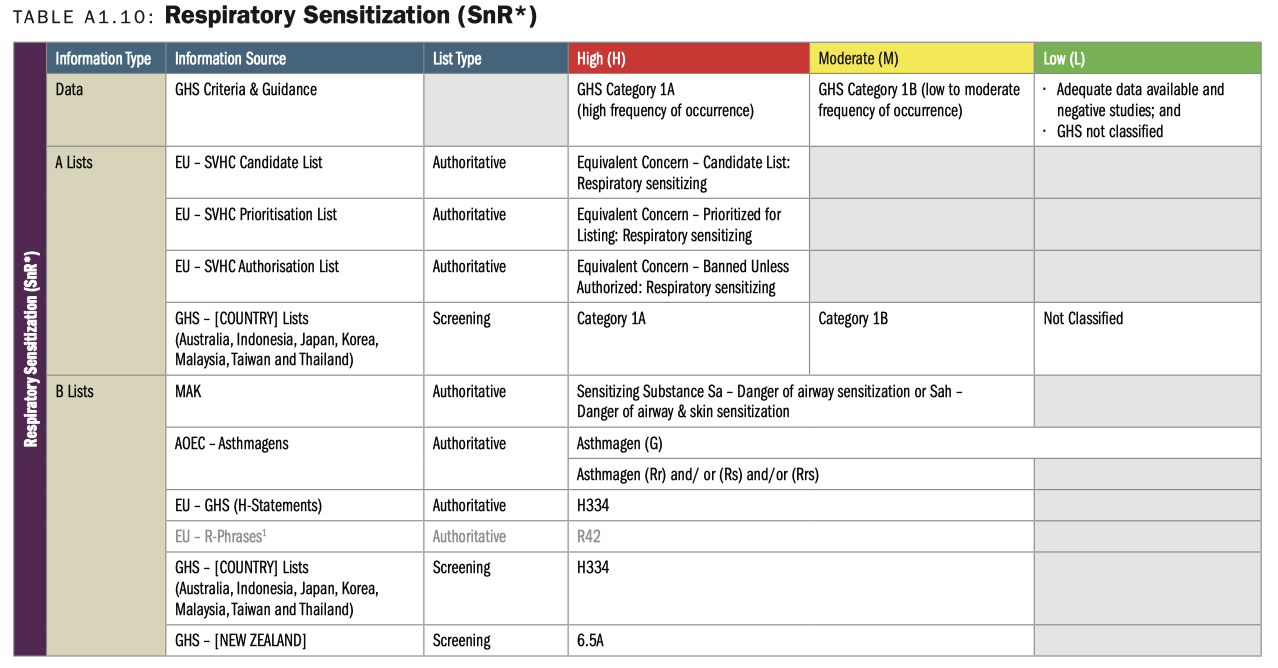
將「化學品危害準則」列表轉換為JSON格式,並且把化學品分類有對應到的準則資訊整筆加入 化學品中的危害評估欄位。一筆化學品資料可能會有多筆危害評估的資料。
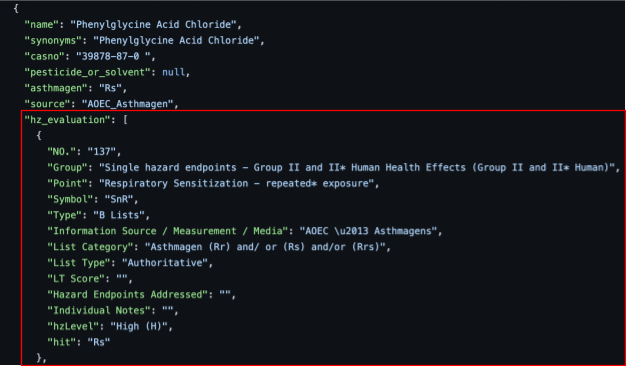
危害評估欄位中,除了包含危害等級分數之外,另存有GreenScreen對於該化學品清單的可信度標準:
依照可信度分為:
- 權威性,可信度相對高。
- 篩選性,可信度相對低。
依照分類定義清楚程度分為:
- A清單:可清楚對應到單一種危害等級,分類清楚
- B清單:橫跨兩種以上等級,包含多種危害終點,分類模糊。
清單的可信度與分類定義清楚程度請見以下表格:
| 清單名稱 | 可信度 | 分類定義清楚程度 |
|---|---|---|
| 歐盟高度關切物質候選清單 | 相對高 | 危害等級分類清楚。 |
| PubChem資料庫 聯合國GHS | 相對低 | 危害等級分類清楚。 |
| Toxics Release Inventory Pb Ts | {:Authoritative=>"相對高", :Screening=>"相對低", :screening=>"相對低", :A=>"危害等級分類清楚。", :B=>"包含多種危害終點,危害等級分類模糊。"} | {:Authoritative=>"相對高", :Screening=>"相對低", :screening=>"相對低", :A=>"危害等級分類清楚。", :B=>"包含多種危害終點,危害等級分類模糊。"} |
| 美國環保署CompTox資料庫 | 相對高 | 包含多種危害終點,危害等級分類模糊。 |
| Us Nih Reproductivve & Developmental Monographs | {:Authoritative=>"相對高", :Screening=>"相對低", :screening=>"相對低", :A=>"危害等級分類清楚。", :B=>"包含多種危害終點,危害等級分類模糊。"} | {:Authoritative=>"相對高", :Screening=>"相對低", :screening=>"相對低", :A=>"危害等級分類清楚。", :B=>"包含多種危害終點,危害等級分類模糊。"} |
當某一個危害終點因不同來源的化學品清單所對照出的分數不同,具有多個評分且有所衝突時,需要依據清單的「可信度」以及「分類定義清楚程度」來給予最終的危害終點評分。如下圖所示:
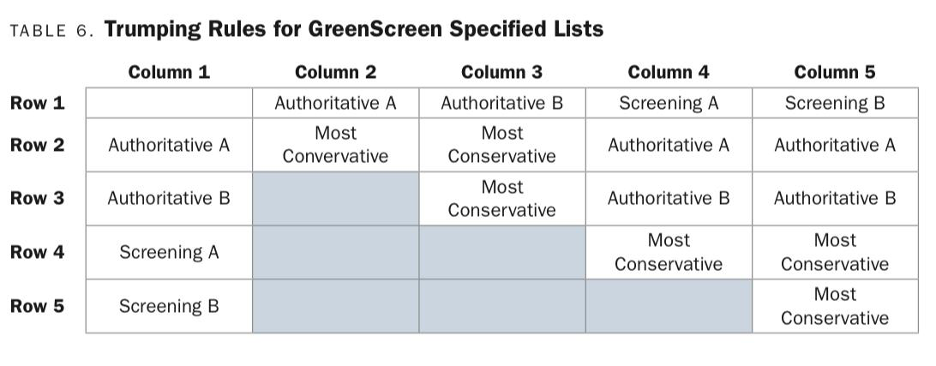
若有一筆兩筆衝突的資料皆權威性清單來源,便是以最保守的資料作為該評分終點的結果。 如:
- 資料來源1:致癌性 - 高危害 - 權威性A清單
- 資料來源2:致癌性 - 中等危害 - 權威性B清單
若有一筆兩筆衝突的資料,其中一筆來自權威性清單,另一筆來自篩選性清單,則以權威性清單的資料作為該評分終點的結果。 如:
- 資料來源1:致癌性 - 中等危害 - 權威性B清單
- 資料來源2:致癌性 - 高危害 - 篩選性A清單
若有一筆兩筆衝突的資料皆篩選性清單來源,便是以最保守的資料作為該評分終點的結果。 如:
- 資料來源1:致癌性 - 高危害 - 篩選性B清單
- 資料來源2:致癌性 - 中等危害 - 篩選性A清單
3. 以CompTox毒理資料制定GreenScreen危害等級分數
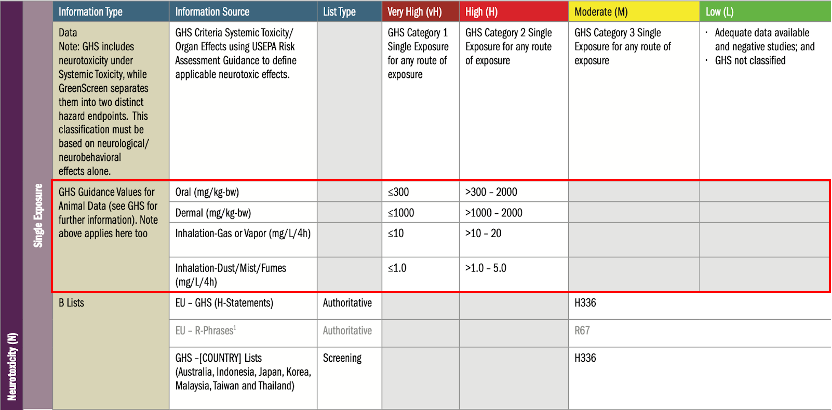
在GreenScreen指引的「化學品危害準則」中,有一類屬於毒性試驗數值資料(出現在急性哺乳類毒性、單次暴露系統毒性、重複暴露系統毒性、單次暴露神經毒性、重複暴露神經毒性、急性水生毒性及慢性水生毒性等七項危害終點),最後也會給予危害等級分數。而每一筆實驗數值資料中,會影響到最後危害等級分數的因素有:
- 實驗中使用的毒理學指標,如:LD50, LC50, EC50…
- 風險評估類型,如:致癌性、環境毒性、慢性致死性…
- 暴露途徑,如:口服、皮膚接觸、吸入…
- 實驗動物種類,大致分成哺乳類及水生生物
- 實驗數值及其單位
對於毒性資料,需要先根據上述的資訊來判斷實驗本身屬於GreenScreen中哪一項危害終點。最後對應到表中的數值範圍來給予該筆資料一個危害等級分數,毒性資料就可以作為實驗中所研究的化學品危害評估的資料之一。
4. 以QSAR模型制定GreenScreen危害等級分數
4.1 簡介QSAR
定量構效關係(Quantitative Structure-Activity Relationship, QSAR)是一個常見用於預測毒性的方法。其理論基礎透過大量的實驗數據以及化學結構的特性作為訓練資料,訓練出一預測模型,藉以推估化學品的毒性,以減少動物試驗的實驗次數,作為一非動物性替代方法。
根據經濟合作暨發展組織(OECD)於2004年11月的決議 [1],QSAR模型應提供以下五點資訊:
- 有完整定義的預測終點(endpoint)
- 有明確的演算法
- 有明確定義的可預測範圍(applicability domain)
- 有使用適當的方法測驗預測準確度
- 若可行時,有提供預測機制的解釋
本計劃採用OECD所提供之原則,來設計QSAR模型,以彌補預測終點的空缺值。以「致癌性」危害終點為例,以下為詳細的方法說明。
4.2 預測終點(endpoint)
以下所描述之QSAR模型的預測終點為「致癌性」。即係指可能或證實具有致癌性風險的化學品會被歸類為陽性(positive);不具有相關危害的化學品將會被歸類為陰性(negative)。
若預測為陽性,則會歸為高度/中度危害 (H/M),為求保守起見,SAS系統內採以高危害作為判斷。反之,若預測為陰性,則被歸為低度危害 (L)。
4.3 QSAR演算法
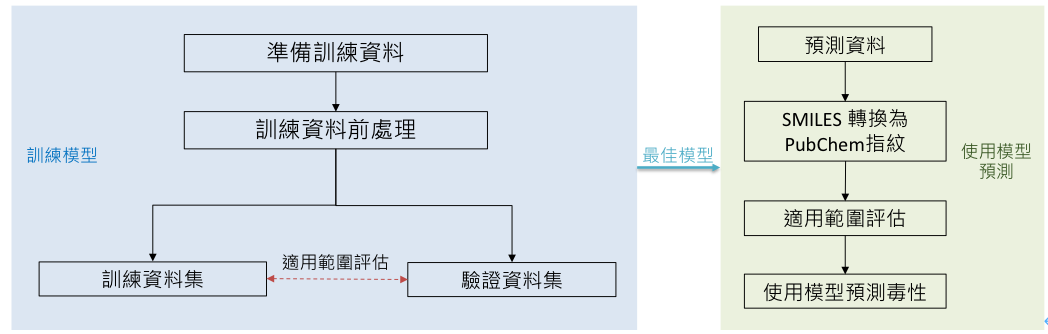
下圖為QSAR演算法的大致流程。首先需要準備一批訓練資料,並經由前處理後,拆分為訓練資料集與驗證資料集,接著使用訓練資料及進行模型訓練,並透過驗證資料及進行效果評估,以挑選最佳的模型以供預測。而預測資料則是會先將SMILES表示式轉換為PubChem指紋後,經適用範圍評估後,確認化學品位於適用範圍內,才加以用模型預測毒性。以下將分述各步驟流程。
4.3.1 準備訓練資料
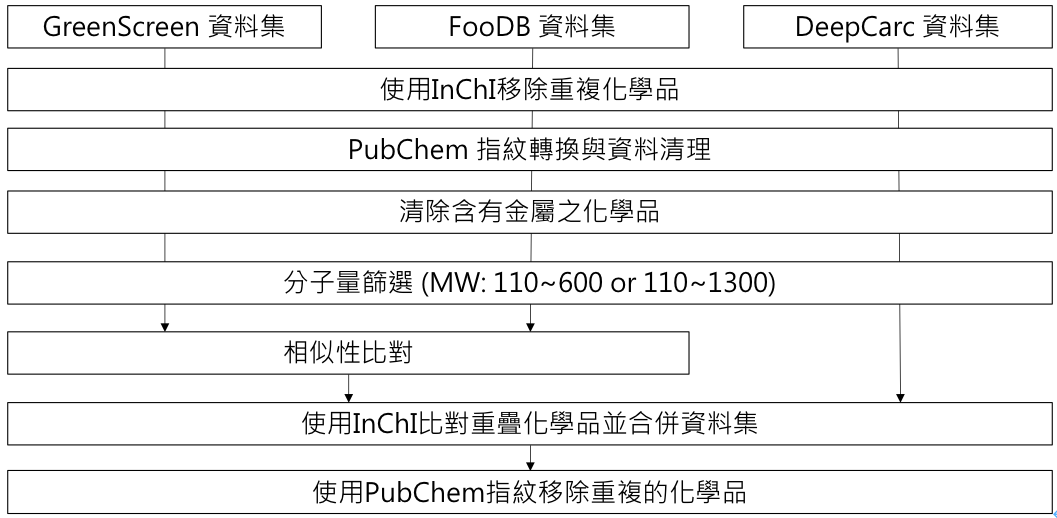
訓練資料來源有三者:
- 本計劃基於GreenScreen指引所整理的資料集 (資料量=1440筆)。此資料集整合多種來源的化學清單,由於多數清單為正面表列,即具有致癌性危害才做記載,因此多記載具有「高」、「中」致癌性危害的化學品,在QSAR當中記載為陽性(positive)。
- FooDB [2] (資料量=70477筆)。此資料集為一免費公開的食品相關資料庫,其中記載了會出現在食品當中的化學組成成分,這些化學成分可能使得這些食品具有香味、色澤、口感、質地、香氣等等,因此在QSAR模型的建立當中作為陰性(negative)。
- 由DeepCarc團隊所整理的致癌性資料集 [3] (資料量=863筆)。此資料集原始來源為美國食藥署國家毒理研究中心肝癌資料庫 (National Center for Toxicological Research liver cancer database, NCTRlcdb) 以及致癌效價資料庫 (Carcinogenic Potency Database, CPDB),並排除掉無機化合物、混合物與有機金屬化合物,其中包含了陽性(positive)與陰性(negative)的化學品。
4.3.2 訓練資料前處理
由於訓練資料來源不同,需要進行整併,如下圖。首先,確認各來源資料每一筆化學品資料皆有簡化分子線性輸入規範 (SMILES) 字串用於表示化學結構,剔除未含有SMILES的資料。接著,透過國際化合物標識 (InChI) 來確認單一來源的資料集中重疊的化學品項目,並透過剔除重複的項目。接下來,利用PaDEL [4] 將各來源的SMILES字串轉換成PubChem指紋(PubChem fingerprint) [5],並剔除無法被轉換為PubChem指紋的化學品。
由於本計畫所設計QSAR模型希望排除無機化合物、大分子聚合物以及金屬有機物,因此經由PubChem指紋清理後,首先透過SMILES字串分析剔除具有金屬的化學品,接著選擇兩種不同區間的分子量篩選範圍 (分子量: 110 g/mol ~ 600 g/mol、110 g/mol ~ 1300 g/mol),作為兩種不同適用範圍的訓練資料集。
排除之元素定義: Sc, Ti, V, Cr, Mn, Fe, Co, Ni, Cu, Zn, Y, Zr, Nb, Mo, Tc, Ru, Rh, Pd, Ag, Cd, La, Ce, Pr, Nd, Pm, Sm, Eu, Gd, Tb, Dy, Ho, Er, Tm, Yb, Lu, Ac, Th, Pa, U, Np, Pu, Am, Cm, Bk, Cf, Es, Fm, Md, No, Lr, Hf, Ta, W, Re, Os, Ir, Pt, Au, Hg, Rf, Db, Sg, Bh, Hs, Mt, Ds, Rg, Cn, Al, Ga, In, Tl, Sn, Pb, Bi, Si, Ge, As, Sb, Se, Te, Po, At。
此外,由於FooDB資料集作為陰性 (negative) 的資料集來源,其資料量遠多於作為陽性 (positive) 的GreenScreen資料集,為減少由於資料不平衡所造成的分析誤差,FooDB資料集於合併前,將先與GreenScreen資料集進行相似性比對,並保留FooDB中相似於GreenScreen資料集的項目。
相似性比對方法如下:
- FooDB中的化學品一一與GreenScreen資料集進行相似性比較。
- 利用python3中sklearn套件的最鄰近搜索 (Nearest Neighbors),找出查找目標 (query) FooDB化學品之PubChem指紋最接近的5個GreenScreen化學品。
-
透過PubChem指紋計算谷本係數 (Tanimoto coefficient),一一計算查找目標的化學品 (query) 與最接近的5個GreenScreen化學品的谷本係數,並取平均,以求得查找目標的化學品 (query) 相對於GreenScreen資料集的平均相似程度。
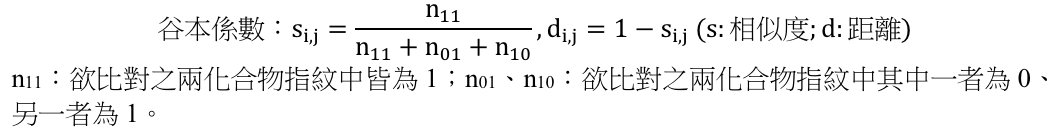
- 設定谷本係數之距離為0.5作為相似性比對之閾值,保留位於距離內之FooDB化學品,其餘則丟棄不用。
經由相似性比對後,接著將進行資料集合併,使用InChI來比對重疊之化學品項目,若發現有標籤衝突之重疊化學品,將以優先順序:GreenScreen資料集 > DeepCarc資料集 > FooDB資料集,以作為標籤。理由為GreenScreen資料集來源皆為政府等公正機關整理隻致癌性相關清單,過去已有許多實驗證實可能或確實有致癌性的危害,而DeepCarc資料集則來自於美國食藥署,亦具有公信力,而FooDB資料是利用其出現在食物的特性,以填補陰性的資料,故順位最後。
最後,合併完資料集後,使用PubChem指紋來移除重複的化學品項目,確保指紋對應到標籤為一對一之關係。
4.3.3 訓練資料集與模型訓練方法
訓練資料進行前處理完成後,將會被拆分成訓練資料集以及驗證資料集。其中訓練資料集將會被用於定義可預測範圍 (applicability domain),以及用於模型訓練中;驗證資料集則是用於評估模型精準度,並挑選最佳的模型以供模型預測用途。拆分訓練與驗證資料集的部分,將會使用不同的拆分亂數種子 (random seed) 重複十次,以得知平均的模型訓練表現。
4.3.3.1 定義可預測適用範圍 (applicability domain)
可預測範圍須符合三個條件:
- 化學品應不包含前述所排除之元素,若含有該元素,則不在可預測適用範圍內。
- 化學品應符合採用之訓練資料集所在的分子量區間,如:使用分子量110 g/mol ~ 600 g/mol之訓練資料集,則可預測適用範圍則為位於使用分子量110 g/mol ~ 600 g/mol的化學品。
-
化學品應與訓練資料集中的化學品有足夠高的相似度,須至少高於訓練資料集中第95分位數之相似度。相似度計算方法如下:
- 首先,利用python3中sklearn套件的最鄰近搜索 (Nearest Neighbors),找出查找目標化學品 (query) 之PubChem指紋最接近的5個訓練資料集化學品。
-
透過PubChem指紋計算谷本係數 (Tanimoto coefficient),計算查找目標的化學品 (query) 與最接近的5個訓練資料集化學品的谷本係數,並取平均,以求得查找目標的化學品 (query) 相對於訓練資料集的平均相似程度。
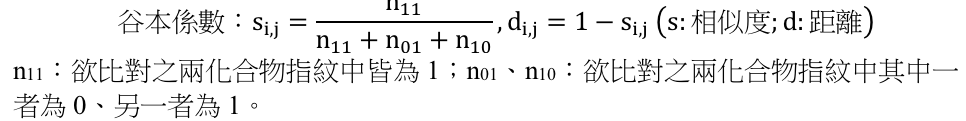
- 依相同方法一一計算各訓練資料與訓練資料集母體之平均相似程度,並排序找出訓練資料集中第95分位數之相似度,作為評斷標準。
- 比較查找目標的化學品 (query) 與訓練資料集中第95分位數之相似度,若相似程度高於該評斷標準(距離夠小),則認定位於可預測適用範圍內;反之則不可預測。
-
此外,本計劃亦有採用另一相似程度計算函式——曼哈頓距離 (Manhattan or city-block distance) 用於(b)之平均相似程度計算,其餘流程(a)-(d)皆相同。

4.3.3.2 模型採用與訓練方法
模型採用支持向量機(support vector machine, SVM)、C5.0決策樹模型、隨機森林(Random forest)三種方法進行模型訓練與預測。
SVM是透過核函數將資料轉換到高維度,並在高維度的空間中找到一個超平面,藉以區分兩類不同的標籤,此即為「具有致癌性」與「沒有致癌性」。其中,SVM採用兩種不同的核函數(kernel function)進行訓練:多項式核函數(polynomial kernel, poly)、徑向基函數核函數(radial basis function kernel, rbf)。SVM在訓練過程中,有超參數(hyperparameter) C及γ (當使用rbf kernel時)需要進行選擇與調整,因此將會使用10-份交叉驗證法 (10-fold cross validation) 搭配隨機搜尋 (random search)來進行超參數的調校,即把訓練資料集拆分為十等份,其中一等份作為內部驗證資料集,其他九等份作為訓練資料,並一一訓練,並將訓練表現進行平均,以得到該組超參數下的平均表現,並隨機產生另一組超參數,重複上述十等份拆分與模型訓練,以找出最佳的超參數設定。
C5.0決策樹模型則是根據訓練資料產生出一棵樹,透過特徵的拆分,找出訓練資料中的分類規則,藉以用於新資料的預測。其中C5.0決策樹模型仍有超參數需要去做選擇——最大決策樹深度 (max depth)、葉子節點最少樣本數 (min samples leaf),同樣採用10-份交叉驗證法搭配隨機搜尋進行超參數調校。
隨機森林則是將訓練資料進行隨機抽取,產生出多棵決策樹,並透過多數決方式進行預測與分類。隨機森林超參數調校項目有最大決策樹深度 (max depth)、内部節點再劃分所需最小樣本數 (min samples split),同樣採用10-份交叉驗證法搭配隨機搜尋進行超參數調校。
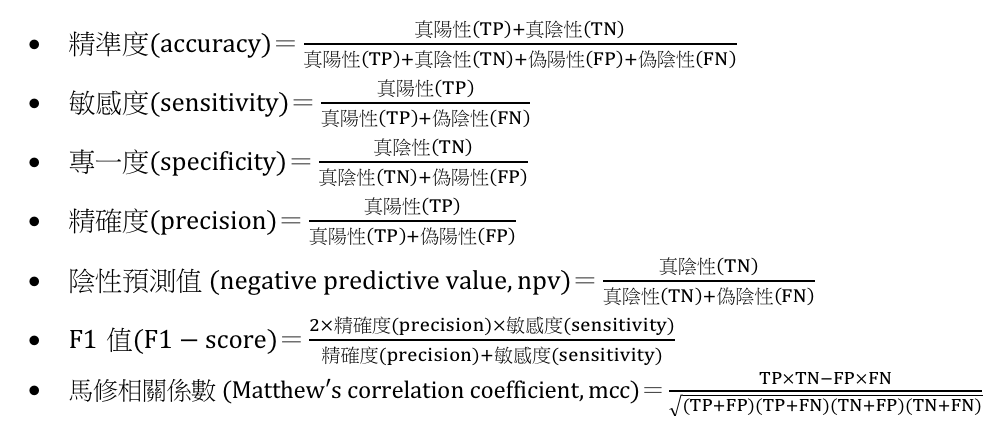
模型評估指標採用精準度 (accuracy)、敏感度 (sensitivity)、專一度 (specificity)、精確度(precision)、陰性預測值 (negative predictive value, npv)、F1值 (F1-score)、馬修相關係數 (Matthew's correlation coefficient, mcc)。評估指標計算公式如下:
4.3.4 試操作12項化學品
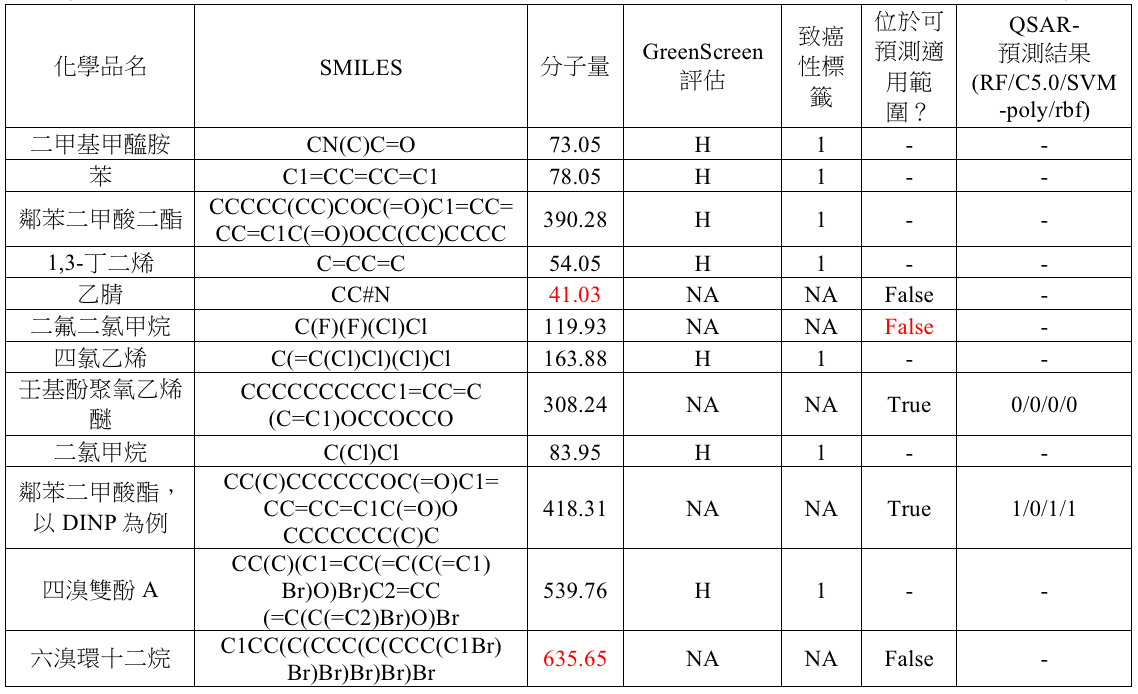
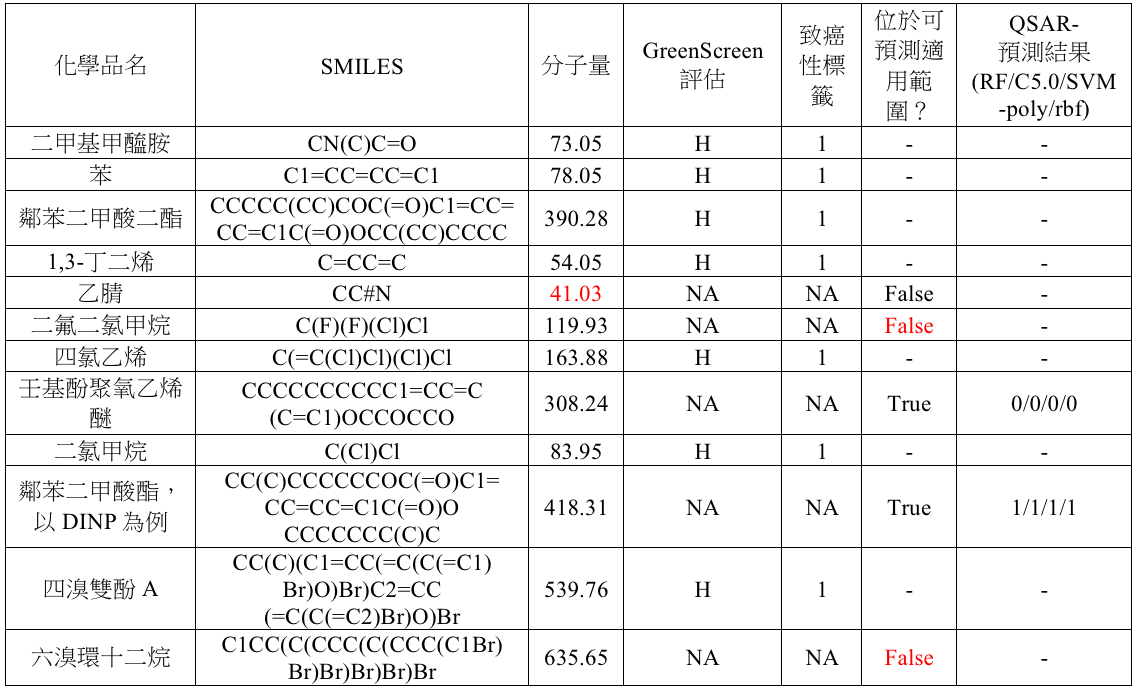
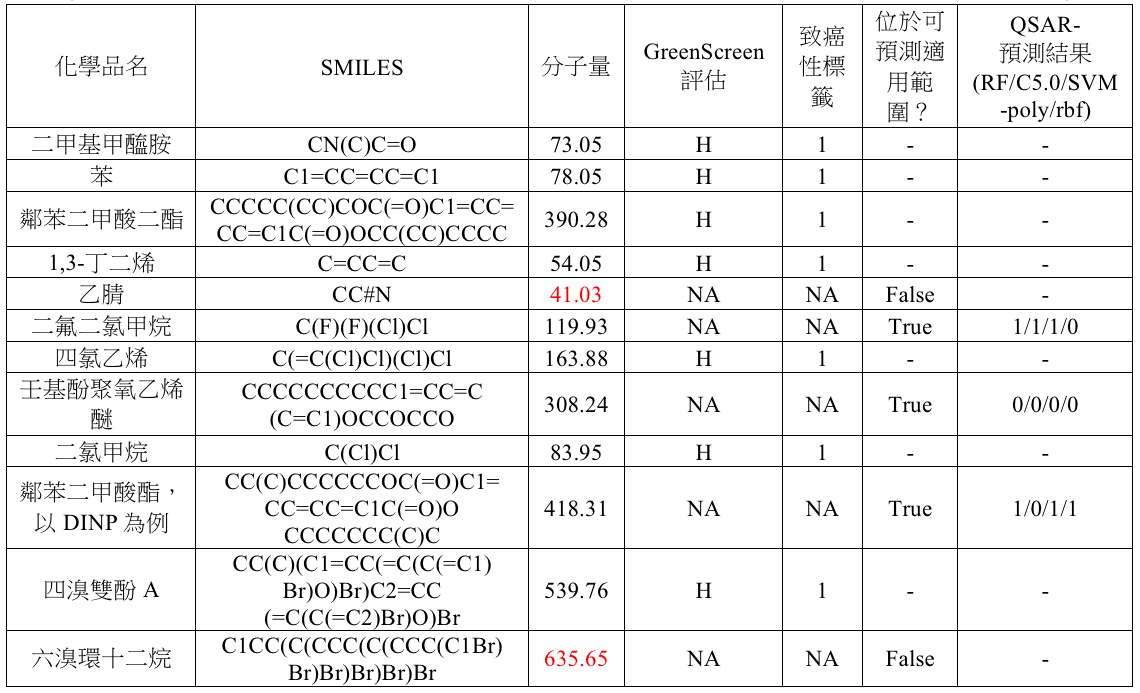
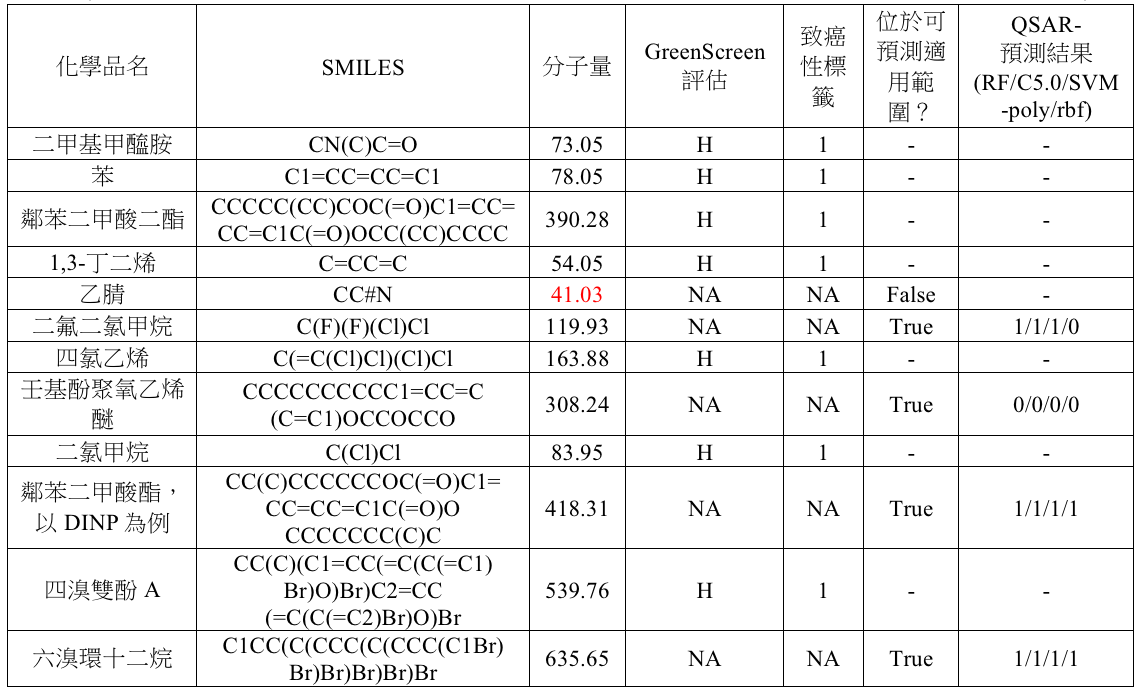
試操作12項化學品有:二甲基甲醯胺、苯、鄰苯二甲酸二酯、1,3-丁二烯、乙腈、二氟二氯甲烷、四氯乙烯、壬基酚聚氧乙烯醚、二氯甲烷、鄰苯二甲酸酯,以DINP為例、四溴雙酚A、六溴環十二烷。其中已有致癌性標籤並顯示具有危害的化學品有七項:二甲基甲醯胺、苯、鄰苯二甲酸二酯、1,3-丁二烯、四氯乙烯、二氯甲烷、四溴雙酚A。剩下五項則為欲預測之化學品。
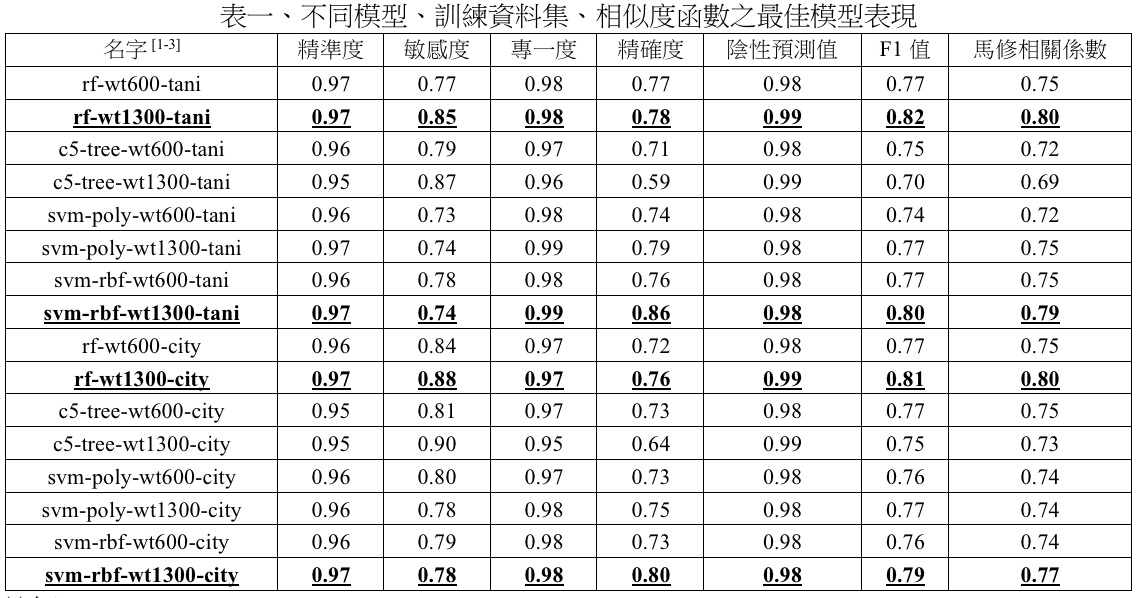
表二顯示採用谷本係數與分子量110 g/mol ~ 600 g/mol之訓練資料集之最佳模型的預測結果。其中乙腈、六溴環十二烷因分子量而無法預測;而,二氟二氯甲烷因相似程度不足而無法預測;壬基酚聚氧乙烯醚預測結果為無致癌性風險;鄰苯二甲酸酯中DINP則因多數決判定為有致癌性風險。
同樣採用谷本係數,但改以分子量110 g/mol ~ 1300 g/mol之訓練資料集進行模型訓練,表三顯示最佳模型的預測結果。其中,乙腈同樣因分子量而無法預測;而,二氟二氯甲烷與六溴環十二烷因相似程度不足而無法預測;壬基酚聚氧乙烯醚預測結果為無致癌性風險;鄰苯二甲酸酯中DINP則是有致癌性風險。
若改採用曼哈頓距離作為相似度計算之函數,將影響到化學品的可預測適用範圍。以分子量110 g/mol ~ 600 g/mol之訓練資料集為例,最佳模型的預測結果如表四。其中乙腈、六溴環十二烷因分子量而無法預測;其餘皆可預測,可以多數決判定最終結果。壬基酚聚氧乙烯醚預測結果為無致癌性風險;二氟二氯甲烷、鄰苯二甲酸酯中DINP則為有致癌性風險。
若採用曼哈頓距離與分子量110 g/mol ~ 1300 g/mol之訓練資料集訓練模型,最佳模型的預測結果如表五。其中乙腈因分子量而無法預測;其餘皆可預測並以多數決判定最終結果。壬基酚聚氧乙烯醚為無致癌性風險;二氟二氯甲烷、鄰苯二甲酸酯中DINP、六溴環十二烷皆有致癌性風險。
4.4 參考資料
- [1] OECD PRINCIPLES FOR THE VALIDATION, FOR REGULATORY PURPOSES, OF (QUANTITATIVE) STRUCTURE-ACTIVITY RELATIONSHIP MODELS. URL:https://www.oecd.org/chemicalsafety/risk-assessment/37849783.pdf
- [2] FooDB. URL: https://foodb.ca/
- [3] Li, T., Tong, W., Roberts, R., Liu, Z., & Thakkar, S. (2021). DeepCarc: Deep learning-powered carcinogenicity prediction using model-level representation. Frontiers in Artificial Intelligence, 4.
- [4] Yap, C. W. (2011). PaDEL‐descriptor: An open source software to calculate molecular descriptors and fingerprints. Journal of computational chemistry, 32(7), 1466-1474.
- [5] PubChem Substructure Fingerprint v1.3. URL: https://web.cse.ohio-state.edu/~zhang.10631/bak/drugreposition/list_fingerprints.pdf
GreenScreen危害評估等級
18項GreenScreen危害終點已根據上述第二、第三部分之「制定GreenScreen危害等級分數」的方法給予各個危害終點的GreenScreen危害等級分數(如:非常高危害(vH)、高危害(H)、中等危害(M)、低危害(L)、非常低危害(vL))或給予一個缺乏資料的標籤「DG (Data gap)」。根據這些危害等級分數,GreenScreen分別針對了有機化合物與無機化合物提供了一套算法,來評估該化合物的綜合評分,即GreenScreen基準評分。基準評分總共分為五個等級:1、2、3、4、U。等級1化學品應避免使用,需要高度關注;等級2化學品則不建議使用,應找尋合適的替代化學品;等級3化學品可以接受使用,但仍有機會改進;等級4的化學品屬於較為安全的化學品,可以使用,並可作為其他等級的安全替代物;等級U則代表危害終點資料有所缺乏過多(DG過多),無法確認分數。
GreenScreen算法則是以條件判別式來依序檢查,等級1的條件是優先檢查,若該化學品有符合的條件判別式,接著會針對符合的判別式進行資料完整度評估以判定是否可以指派為該等級化學品或指派為「不確定分數」,若有符合資料完整度要求,則被指派為等級1化學品;若該化學品在所有等級1的條件皆未符合,才接著往等級2的條件進行檢查,以此類推。整體而言採保守原則,即高危害優先於低危害,而高危害基準評分對於資料完整度要求低,低危害基準評分對於資料完整度要求高。
| 基準分數 | 有機化合物標準 | 無機化合物標準 | 資料完整度 |
|---|---|---|---|
| 等級 |
|
|
人類健康組中僅需一項危害終點達標準,其餘人類健康組之危害終點皆可允許資料缺乏 |
| 等級 |
|
|
|
| 等級 |
|
|
|
| 等級 |
所有危害均為低或非常低 |
持續性不限,其餘危害皆為低或非常低 |
不允許任何資料缺乏 |
| 等級 | 資料不足無法判別。 | ||
GreenScreen清單轉譯器等級
GreenScreen清單轉譯器與第二部分「以化學品清單制定GreenScreen危害等級分數」方法類似。與第二部分不同,GreenScreen清單轉譯器參考GreenScreen Guideline v1.4中的附錄十二「GreenScreen清單轉譯器地圖」所列出來自不同國家、政府機構或非政府組織的化學品清單,將各個清單所區分之危害分類對應到GreenScreen對於化學品危害程度區分出的五個等級分數,分別為:非常高危害(vH)、高危害(H)、中等危害(M)、低危害(L)、非常低危害(vL),此外,清單轉譯器會額外分出3種清單轉譯器分數:等級1、等級P1、等級UNK。當化學品屬於等級1,代表等價於GreenScreen基準評分之等級1,屬於避免使用範疇,應積極尋找安全替代物;若屬於等級P1,代表極有可能為GreenScreen基準評分之等級1,可能屬於應避免使用的化學品,需要進一步檢查是否符合GreenScreen基準評分等級1之條件,或進行完整的GreenScreen評估最終基準分數,以決定其是否為一個能夠安全使用的化學品;等級UNK代表無法從現有的資料來斷定其危害程度,應進行完整的GreenScreen評估最終基準分數。
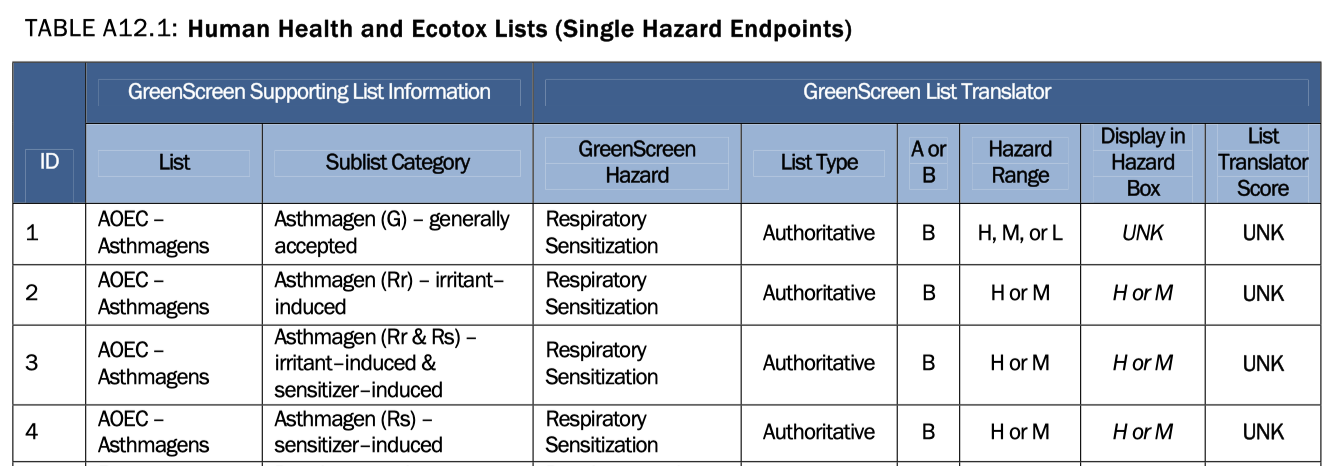
同樣以下以AOEC Asthmagen化學品清單為例說明:
例子1:Tosylalaye dihydrate
原始化學品清單中資料顯示為”R”,可以對應到GreenScreen清單轉譯器地圖ID 2 (如下圖所示)。因此危害終點為「呼吸致敏」,危害等級為H or M (在資料庫當中記做兩筆資料),清單轉譯器評分為UNK。
例子2:Phenylglycine Acid Chloride
原始化學品清單中資料顯示為'Rs',可以對應到GreenScreen清單轉譯器地圖ID 4 (如下圖所示)。因此危害終點為「呼吸致敏」,危害等級為H or M (在資料庫當中記做兩筆資料),清單轉譯器評分為UNK。
附錄
無機化合物基準評分判定流程

有機化合物基準評分判定流程
